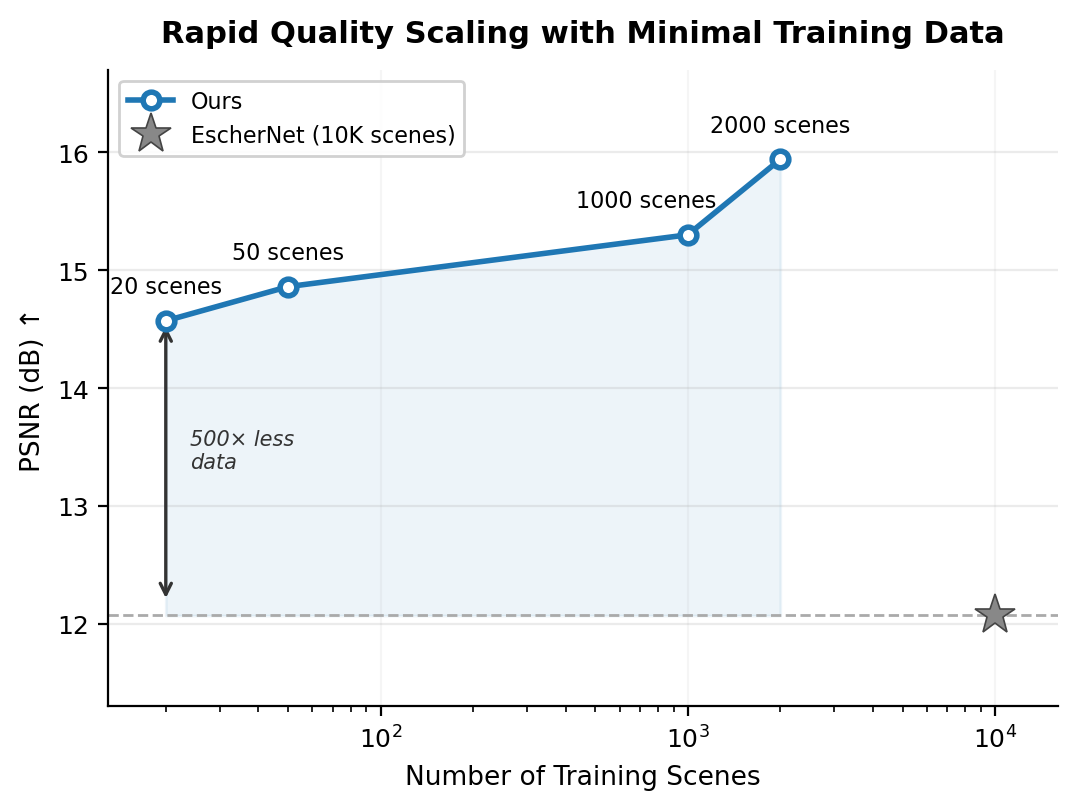




















































































We visualize the effect of key design choices on the same target view. Each example shows the 6 input views and the ground-truth target, followed by ablation variants: (a) w/o per-view encoding, (b) w/o pixel unshuffle, and (c) our full model.
Without per-view independent encoding, the causal VAE entangles information across frames, producing severely corrupted outputs that bear little resemblance to the target view. Without pixel unshuffle, the ray map geometry is lost during downsampling, leading to plausible but inaccurately posed generations that fail to align with the target camera.